Stay in Control
Budgets and retries
The two bounds on repeated agent work — budgets that cap spend across scopes, retries that cap repeated attempts.
Repeated work is where cost and effort quietly accumulate, and Task Machine bounds it in two directions: a budget caps how much can be spent within a scope, and standard retries cap how many times failing workflow work tries again. Approvals and verifiers (see approvals and verifier gates) keep a process under judgment; budgets and retries keep it from drifting past its limits while it runs on its own. This page describes what each one models and how far each is wired today.
A budget caps spend within a scope
A budget is a limit attached to a part of your work. Each budget names a scope — the thing the limit applies to — and Task Machine supports a budget at any of these levels:
- Workspace — a ceiling for the whole operating context.
- Project — a limit for one project's work.
- Goal — a limit for the work pursuing one goal.
- Task — a limit for a single piece of work.
- Agent — a limit on what one agent may spend.
- Workflow — a limit for a repeating process.
- Team — a limit on the work a team's members do.
A budget carries a monetary limit and currency, token limits for input, output, and cache-write usage, a period it resets over — daily, weekly, monthly, quarterly, yearly, or one-time — and a status. The scopes overlap by design: a tight per-agent limit can sit inside a looser project budget, so you bound the part you worry about without re-stating the whole. Because a budget is scoped and periodic, it expresses an operating intent — "this agent gets this much per month" — rather than a one-time cap. Budgets are separate from billing: they bound operational usage and do not touch checkout, subscriptions, or entitlements.
You manage budgets from a dedicated screen in the workspace. The Budgets page lists every budget you can see — split into active and archived — with each one's scope, period, limit, and where its spend stands against that limit right now.
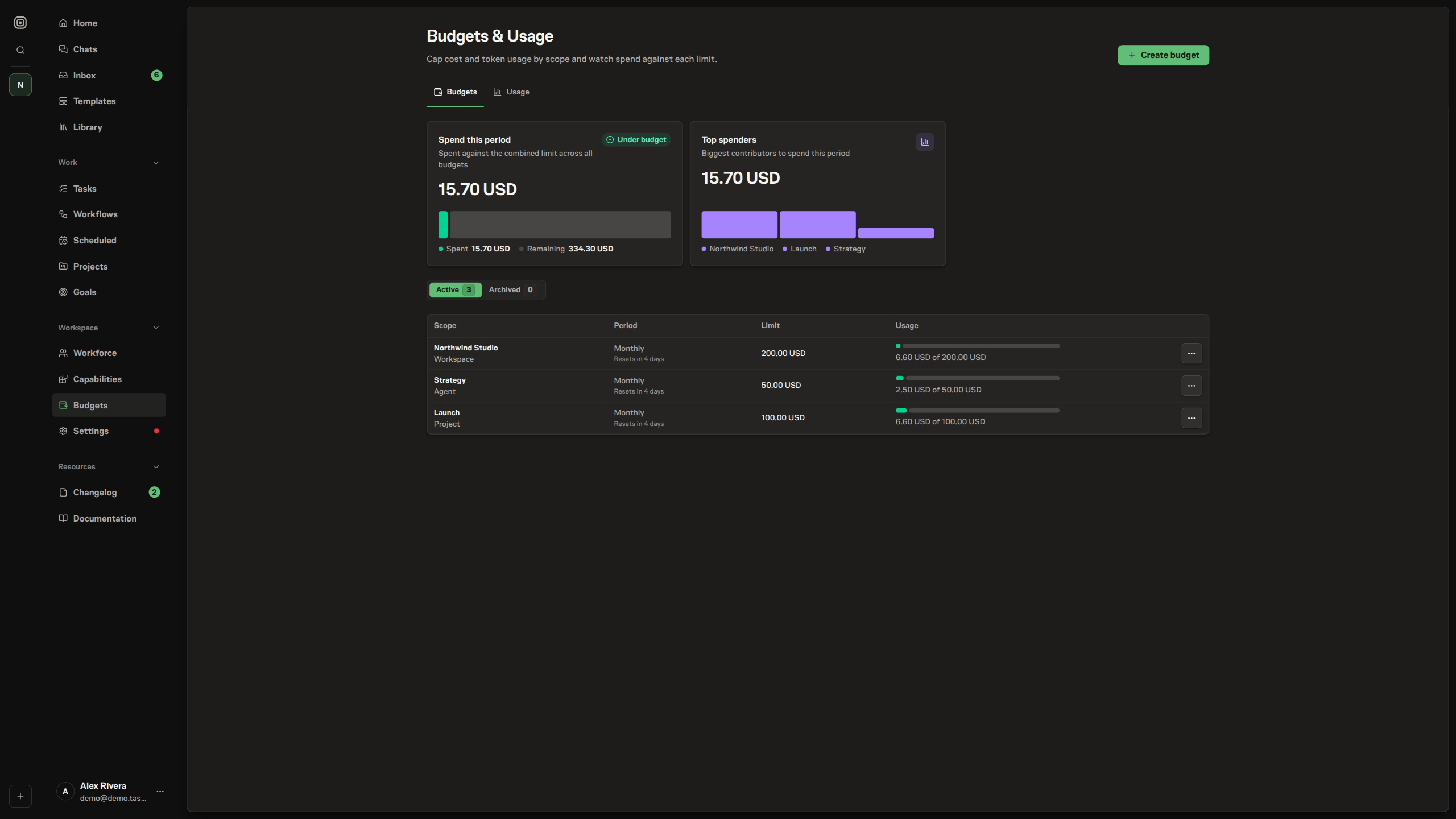 From there you create a budget by choosing a scope and setting its cost or token limits, edit a budget's limits and period, and archive a budget you no longer want tracked or restore one you do, all live across sessions. Creating, editing, and archiving require the budget-manage permission; the page stays viewable to anyone with read access and hides the controls from members who only watch.
From there you create a budget by choosing a scope and setting its cost or token limits, edit a budget's limits and period, and archive a budget you no longer want tracked or restore one you do, all live across sessions. Creating, editing, and archiving require the budget-manage permission; the page stays viewable to anyone with read access and hides the controls from members who only watch.
A budget tracks spend and stops work that exceeds it
A budget is not just a recorded intent — Task Machine measures real usage against it and acts when a limit is reached. Every run an agent does on a connected machine records its cost and token usage, and a budget sums that usage across the work in its scope for the current period. Spend is read from each run's standardized cost: the cost of every model call is normalized to a single base currency and then converted into the budget's own currency, so a budget set in euros and work paid for in dollars still compare cleanly. The Budgets page shows that spend next to each limit, and marks a budget as near its limit or over it so you can see at a glance which ones need attention.
The same measurement drives two kinds of action. As a budget approaches its ceiling, Task Machine warns the people who manage budgets: when usage crosses a high-water mark or passes the limit, a notice lands in the inbox for every member who can manage budgets, deduplicated so one period raises one warning per threshold rather than a stream. And when a budget is fully exhausted, it does more than warn — Task Machine refuses to start new agent work in that scope. Before an agent run begins, the active budgets covering its task, project, goal, agent, workflow, and workspace are checked against current usage; if any is over its cost or token limit, the run is paused, the refusal is written onto the task's timeline so the reason is visible in the papertrail, and the queued job is cancelled rather than left to spend past the cap.
Agents can see a budget and ask for more
A budget is not only something an agent runs into — it is something the agent can read and respond to. From its runtime an agent sees the budgets that govern its work, each with how much of the limit is already spent and whether it is near or over, so a careful agent checks its remaining room before starting expensive work rather than discovering the ceiling by being stopped at it.
When an agent is about to exceed a limit it does not silently stall: it can request a budget increase, naming the budget, the higher limit it needs, and why. That request changes nothing on its own — it lands in the inbox for the members who manage budgets, who raise the limit by approving it or decline by rejecting it with a reason. Where a scope has an owner the ask is theirs to make: a budget on a goal or team can only be raised at the request of that goal's or team's lead, while budgets on the workspace, a project, a task, an agent, or a workflow are open to any agent working in that scope. Either way a human decides — the agent advocates for more room but never grants it to itself. Reading budgets and opening these requests are tama budget commands; see the CLI command reference.
See where spend is going
Limits are only half the picture; the other half is seeing where cost and tokens actually go. The Budgets page carries a second tab, Usage, that turns the same recorded run usage into workspace analytics. It shows the period's total spend and token counts, a cost-or-token trend over time you can read by day or by week, and a top-spenders breakdown you switch between agents, projects, tasks, and runtimes — so you can tell which agent, which project, or which runtime is driving the bill. A period control narrows the window from this month down to a single day, or widens it out to all time.
Every place a budget can be scoped also carries its own usage. A task, goal, project, or workflow detail page shows a card with the cost accumulated across every agent run on it, the input, output, and cache token breakdown, and — when a budget covers that scope — the budget's status and when it next resets, shown as the day it resets or, within a week, how long until it does. If you manage budgets, you can set a budget for that resource, or edit the one already covering it, right from the card: it opens the same budget form as the Budgets page, already scoped to what you are looking at.
Standard retries cap repeated attempts
Where a budget bounds spend, standard retries bound repeated effort: how many times a workflow step tries again after it fails. Task Machine keeps that bound out of the builder so a process author does not have to tune infrastructure details for every node. A runtime failure or timeout retries automatically with a fixed exponential backoff and a small maximum attempt count. A verifier invalid outcome or an artifact step that missed its promised output gets one rework attempt with the feedback folded into the next run of that step.
The important point is the bound, not the knob. A workflow will not loop indefinitely once it runs on its own: runtime failures, verifier failures, and artifact validation failures all have a defined retry path and a defined point where the run stops and records the reason.
How far retries run today
Workflows now execute with real retry paths, though not the full policy you author. Runtime failures and timeouts retry automatically with a standard exponential backoff before the run fails. A workflow run that hits a missing artifact makes one bounded rework attempt before failing. Verifier gates do not retry automatically: PASS continues, FAIL fails the run, and UNCERTAIN pauses for a human answer. So the policy is real and travels with a published version, while interpreting the full policy — the configured maximum attempts and backoff you set per node — is still to come.
A budget's bound is also live: an exhausted budget pauses new agent work in its scope before it starts. That is the control model to keep in mind: spend is enforced against the limits you set, while repeated effort is bounded by Task Machine's standard retry behavior.
This is the last chapter of staying in control: with surfaces to approve on, gates to verify against, and bounds on spend that hold while work runs, you set where a repeating process acts on its own and where it answers to you. Retry policies are the next bound to become executable.